



Is It Interesting to Say That AI Isn’t That Interesting?
I hope so, because that’s what I wrote about this week.

I haven’t written much about artificial intelligence because it’s neither my area of expertise nor something having much effect at this point on economics, American politics, or public policy. But the hype has reached such a fevered pitch that I’ve felt obligated at least to educate myself on the topic. And I figured I should share what I’m learning, though be forewarned you’re getting thoughts still in development. I’ll probably use some terms imprecisely. Indeed, I’m hoping that my own comments will generate feedback and questions, new information, corrections, and so on.
So, what do I think of AI? I remain deeply underwhelmed. McKayla-Maroney-level unimpressed.
{kind=link}
Obviously, the large language models (LLMs) like ChatGPT that have garnered so much public attention are cool technology. In some contexts, they represent an improvement on traditional search engines and bring a wider range of better-organized information more quickly to the user’s fingertips. They summarize large amounts of text into smaller amounts of text, which is very useful. The most advanced versions, like OpenAI’s new o3 model, show extraordinary mathematical reasoning ability—in some domains of math and science, as well as in writing computer code, they are approaching the performance level of the top humans on some tasks. And of course, the uncanny imitation of various writing styles is an entertaining parlor trick.
AI has the potential to transform various industries and job categories, make lives easier in many ways (and more difficult in many others), and aid scientific discovery and technological progress. In this respect, it is what we would call a “general purpose technology” (yes, coincidentally, also abbreviated GPT), like electricity, the internal combustion engine, the computer, or the Internet. It will also expand the capabilities of “the bad guys,” as all those technologies did as well, creating new threats that will have to be countered.
As with other GPTs, its most effective uses will be discovered slowly, deployment from lab to real world will take years, and the full impact will be felt over decades. Thus, as with other GPTs, our base case should be that AI will represent not some unprecedented break with the prior trajectory of innovation, but rather a breakthrough necessary for the continuation of that trajectory. Historically, as progress from one GPT has been exhausted, another has emerged to grab the baton and sprint ahead. Without new GPTs emerging, we experience stagnation.
Since the start of the industrial revolution, machines in their many forms have replaced virtually all the work humans once did, creating the surge in productivity responsible for modern prosperity and the opportunity to do all the work we now do. The computer allowed mathematicians and scientists to make entire new classes of discoveries. Hopefully AI will too. But these outcomes would not represent a divergence from the past; they would be the continuation of business as usual in the modern era.
Unfortunately, at the moment, all the preceding enthusiasm makes me a Negative Nancy. I asked Claude, the Anthropic chatbot that many consider more advanced than ChatGPT, to suggest some other phrases that start with the letter “n” that mean the same thing as Negative Nancy. For alliterative purposes, I thought it would be fun to throw in a “nattering naybob of naysaying” or what have you. Claude suggested Negative Nate/Nathan, Negative Ned, Negative Norman… and then noted that such phrases “can be dismissive of genuine concerns or feelings someone might have. Would you like to share the context in which you're looking for these phrases? There might be more constructive ways to address someone's negativity.” Yes, Claude, the context in which I’d like to use these phrases is that you provide answers like that one.
“This Time Is Different”
The problem is that the potential of a new general purpose technology is not what people want to talk about when they want to talk about AI. The animating principle of the AI frenzy is that This Time Is Different. Typically, the conversation concerns “Artificial General Intelligence” (AGI) with the potential to replace the economically useful functions of workers entirely or “superintelligence” that will rapidly surpass human achievement, though neither has a useful and consistent definition. People enjoy gazing at their navels while pontificating on whether humans are “creating a god” and what that would mean. “Thought leaders” establish their bona fides by taking seriously worst-case scenarios in which a superintelligent AI “escapes” its servers and methodically proceeds to exterminate the human race.
As a result, seemingly infinite cash has poured forth to establish countless institutes and host a never-ending parade of conferences. The technologists willing to make the most absurd and self-confident pronouncements have become celebrities. And no one wants to call “bullshit”; where’s the fun, or funding, in that? You’re probably bored by this essay. Sorry.
The most important analytical shift we can make in thinking about AI is to place the burden of proof where it belongs, on those making the claim that This Time Is Different, who I will rather clunkily refer to here as the TTIDs. TTIDs do not like having the burden of proof placed on them, because they tend not to have much to offer in the way of substantive argument once the rhetoric has been tabled. I have been shocked in my own conversations how quickly even a bit of pushing leads to a retreat behind the response that, “of course we don’t know what the probability is, but we have to acknowledge that there is some possibility. Maybe it’s 10%, maybe its 1%, maybe its one-tenth of a percent… we still have to think about it.”
Do we? It’s almost impossible to “prove the negative,” showing somehow that something cannot happen. If we accept a mindset that we have to take something seriously unless we can prove that it cannot happen, then we will have to take everything seriously all the time. That would be exhausting, and a very poor use of our limited resources. If we are supposed to take seriously the prospect of an unworldly superintelligence germinating inside a data center somewhere, those who are genuinely excited, or scared, by the prospect should make the affirmative case for its plausibility. So far they’re not doing a very good job.
Here are three things to look for in conversations about AI, before getting too worked up:
1. How are we defining “AGI” or “superintelligence”?
I was surprised to learn that there is no common definition for these terms and that, while each expert will pontificate on their own definition with high confidence, they will also acknowledge quite quickly that other experts have directly conflicting views. In some cases, AGI means capabilities indistinguishable from a human’s, while in others it means excellence in some type of task, or in, say, “80% of economically valuable tasks.” Some folks declared excitedly that OpenAI’s o3 model “reached AGI” because it performed well on the ARC-AGI test, which defines AGI as “a system that can efficiently acquire new skills outside of its training data,” which is an interesting definition, but tells us nothing about the system’s capabilities vis-à-vis humans.
Definitions also exhibit extraordinary levels of slippage in the course of a typical interrogation. TTIDs will eagerly tell you that AGI is right around the corner, but the more you push on what that means and why they are so confident, the more quickly the system they are describing collapses back into… well, roughly what we already have.
In politics, we call this a “motte-and-bailey” argument. As Wikipedia explains:
The motte-and-bailey fallacy is a way of arguing where someone uses two different ideas that seem similar but are not the same. One idea (the "motte") is easy to defend and not very controversial. The other (the "bailey") is more controversial and harder to defend. When someone argues for the controversial idea but gets challenged, they switch to defending the less controversial one. This makes it look like their original point is still valid, even though they are now arguing something different.
In his start-of-year “Reflections” last week, OpenAI’s Sam Altman asserted that, “we are now confident we know how to build AGI as we have traditionally understood it.” But talking to Bloomberg, in an interview also published last week, he demurred, “‘AGI’ has become a very sloppy term. If you look at our levels, our five levels, you can find people that would call each of those AGI, right? And the hope of the levels is to have some more specific grounding on where we are and kind of like how progress is going, rather than is it AGI, or is it not AGI?” (OpenAI has defined five levels as “stages of artificial intelligence,” none of which it calls AGI.)
If Altman were using “AGI” as shorthand in his conversation with Bloomberg, while expounding on the nuance of OpenAI’s five levels on his own blog, we might cut him some slack. But notice he’s doing the opposite: faced with questions from a reporter, he quickly hems and haws about AGI as “a very sloppy term.” Presenting his unfiltered and unchallenged thoughts on his own terms, he casually proclaims his confidence that he knows the solution.
Rather than succumb to the promotional rhetoric, pay attention to substantive and analytical assessments of progress in the current research agenda. Which brings us too…
2. What is the trajectory of progress?
Claims about the extraordinary feats to come from artificial intelligence typically rest on some forward projection based on the rate at which capabilities have been increasing and an assumption that this rate will persist or increase. Unfortunately, that assumption rests on no real foundation at all. (And, indeed, it’s somewhat ironic that the TTIDs premise their assertion that This Time Is Different on an assumption that the future trajectory of this particular technology will not diverge from past experience with it—so This Time Is Different in a steady and consistent way.)
The basic argument is that, as we feed more data into the models and add more computational power to training them (“train time”), and give them more time with that computational power to work through responses (“test time”), their capabilities keep improving. So if we just keep adding more and more data, more chips, and more energy, the sky is the limit. You hear explanations that start, “if we’re tracing lines on the graph…” As one TTID told me earnestly, “the brain is just a neural network. If you throw enough circuitry at it, you will be able to create a digital brain.”
Such unexamined extrapolation is extraordinarily irresponsible. A helpful analog is the famous “Moore’s Law,” which predicted that the number of transistors on a chip would double every two years. This trajectory held for decades and led to the astonishing increase in the computing power of electronic devices. But we also saw that raw computing speed did not necessarily correlate directly to capabilities. In some periods, the technical progress had outsized impact: for instance, when shifting from mainframes to desktop computers. In other periods, a doubling of transistors on a chip accomplished led to nowhere near a doubling of real-world capability.
Do we have reason to believe that more data and more computing power will lead to more capable models indefinitely, without new algorithms that no one has yet conceived? Not really. Indeed, the leading researchers themselves don’t understand well enough how these models work to make meaningful predictions about how they are likely to evolve. More data and computing power does make the model even more effective at predicting the next word in a sentence. The parlor trick can get even better! But whether cramming more chips into a data center can make the chatbots behave like humans, no one knows.
Likewise, insofar as new models are making dramatic strides, they are doing so in narrow domains. TTIDs will rightly highlight the extraordinary value the technology has for generating computer code and doing math problems. That’s very useful. It’s also… what computers have always been for. And the models do it by applying existing human knowledge from the data they ingest, not achieving new breakthroughs beyond human limits.
This last point is important because the final refuge of the TTID is reliance on the concept of “self-improvement.” If we can just get the models good enough, they will start programming themselves to be even better in a runaway cycle of progress that won’t depend on human capabilities at all. This deus ex machina is remarkably convenient and, again, not really supported by much evidence. To the contrary, the very things models do not do now are the things they would need to do for this process to begin.
In all my conversations, I found most clarifying the concept of AGI as near but not total achievement of human capabilities—the “80% of economically valuable tasks.” This, not actual intelligence surpassing humans, is what most TTIDs are confident can be reached. And then the hand-waving begins. The “80%” is such a useful construct because it invites the question, “what’s in the 20%”? One story holds that the 80% is just an arbitrary waystation on the way to 100% and beyond—it doesn’t matter what’s in the 80 and what’s in the 20. But if that were true, why bother thinking about the 80 at all?
No, the far more likely reality is that there’s some set of things that the current AI approach can solve, and another set that it cannot. The right picture is not an exponential curve rising to infinity, but an S-curve whose steep upward segment we are currently riding.
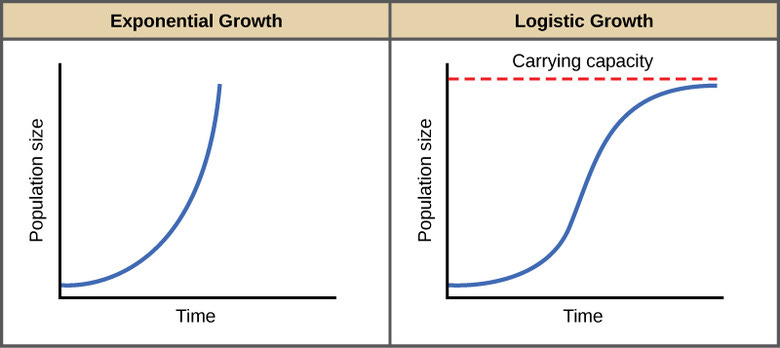
(image via Texas Higher Education Coordinating Board)
One reason for this S-curve is that we can train the models only on knowledge and data that humans already have, or that models themselves can generate. Intuitively, it makes sense that we can build models that do well the things we know how to do. The leap from there to models that can operate entirely beyond the sophistication of the ideas on which they are trained, with capabilities their creators cannot understand, is a leap in kind, not degree, and one not in evidence.
A related issue appears with what’s called algorithmic innovation: the gains made not from cramming more data and computing power into a model but from deploying new conceptual techniques to its design. Progress in neural networks and machine learning, going back decades, exhibits a pattern in which a major algorithmic innovation clears the path to a period of progress where more data and more computing power yields improvements, but that trajectory is never exponential. Always the S-curve emerges, progress slows, and a new algorithmic innovation is needed. Even the progress that OpenAI’s o3 showed over its GPT models required the introduction of new concepts. The current algorithms do not show the ability to achieve even the “80%” definition of AGI, which means that extrapolations of indefinitely and exponentially rising capability from increases in data and computing are wrong. The current algorithms do not show the ability to deliver algorithmic innovation, which means that the theory of self-improving models building an AGI that humans cannot remains science fiction.
All signs point to extraordinary capabilities in narrow quantitative domains with discretely correct answers, and far weaker capabilities elsewhere. There’s no reason to believe, absent further evidence, that throwing more silicon at the problem will clear the hurdles. And if it doesn’t, then the 80% AGI does not become 100% AGI, rather it becomes exactly the sort of general purpose technology that has delivered extraordinary productivity gains in the past while still leaving humans fully in control.
3. Benchmarks and Tripwires
If the burden of proof lies with the TTIDs, they should be eager to develop evidence in support of their case. Generally speaking, this should take the form of “benchmarks”; tests that models could pass that would demonstrate various classes of capabilities. If we could all agree in advance on various sets of benchmarks that would demonstrate broadening capabilities across domains and deepening capabilities to match or outperform humans in each, then we would have a common understanding of what AGI means and how to know if it is actually getting closer.
Unfortunately, benchmarking has thus far been limited almost entirely to highly technical coding and mathematical domains. A community determined to demonstrate how great its models are should be much more eager to create a much broader set of benchmarks simulating real-world challenges and scenarios, and demonstrating to the world how the models perform. Until those emerge, “solved a lot of math problems” should stop garnering headlines.
Of course it’s possible that when the TTIDs say, “systems smarter than the smartest humans are coming,” what they mean is not systems generally able to outperform humans in real life, just systems that do math problems really well. But that would be rather less remarkable; after all, a pocket calculator already performs multiplication much faster than a human can; any computer performs all sorts of tasks that no human ever could. That did not make them smarter than the smartest humans in any way that meant their times were different.
Benchmarks also play the role of tripwires. The various doomsday scenarios associated with AI all assume a sudden and uncontrolled capability emerging from within a system. AGI is treated as a unidimensional phenomenon, with a point at which we “cross the AGI frontier,” underscoring the need to “get across the finish line first.” And if that happened accidentally, or without proper disclosure, disaster might ensue. But that’s not how progress has looked or will look. If we are approaching AGI, it will come in uneven spurts, with sudden improvements in some capabilities but not others as algorithmic innovation occurs. The evidence that models could soon pose some threat will be clear before they have the full set of capabilities to in fact pose the threat.
So benchmarks should not only validate progress, but also provide the basis for credible warnings. Pontificating that AI could someday destroy humanity is rather a waste of time when it cannot yet answer a basic question without hallucinating. But place it in a secure testbed with a facsimile of a banking network and wait to see whether it decides to steal all the money… when it can do that, we’ll need to pay attention.
Commenting on a technology’s limits always poses the risk of repeating Paul Krugman’s famous mistake in 1998, when he wrote that, “By 2005 or so, it will become clear that the Internet’s impact on the economy has been no greater than the fax machine’s.” But there’s no need to compare AI’s likely effect to the fax machine’s. To the contrary, one can acknowledge that the kinds of models now emerging from AI labs are likely to have every bit the impact of the Internet—that is, an enormous, era-defining impact—while still demanding better evidence from AI evangelists for claims that are typically orders of magnitude more extreme.
A technological revolution on par with the Internet is obviously an extraordinary development, with new sets of opportunities and challenges that come around at most once in a generation. If 2050 looks as different from 2020 as 2020 looked from 1990, that will be plenty different enough. But from a social and economic perspective, that difference is no different at all, insofar as 1990 represented a barely recognizable transformation from 1960, and 1960 from 1930. We should celebrate AI as the next general purpose technology in a long line of them, not dismiss it as a fax machine, worship it as a nascent god, or fear it as an extinction-level threat.
I’ll gladly rethink that perspective if evidence to the contrary exists or emerges. And I accept that it might “age poorly” if new breakthroughs occur. My interest is in assessing what we do know, what really is happening, and how we might rationally respond.
- Oren
I do know something about AI, having spent about 10 years in the IT field and played around with developing basic neural networks for fun.
This article is spot on. AGI is likely a pipe dream. I believe that for both technical and philosophical reasons. For postliberals who actually want to try and improve the world, the AI-related low-hanging fruit is erotic chatbots and deepfake video.
Erotic AI chatbots can already produce a Choose-Your-Own-Adventure style narrative, but the story never ends and can be adapted instantly to any fantasy you have. It is INCREDIBLY addictive. I respect if that sounds like a minor problem, but with a birthrate of 1.6 already, what percentage of men will choose this Matrix-like world, particularly as it "improves"? Right now it's text with a few AI generated pictures; we're maybe 3 years away from being able to do the same with real-time, interactive video. You think today's porn and video games are bad; you have no idea what's coming. If you believe in virtue at all, this requires your attention.
The same AI video technology can already produce CCTV level deepfakes that are indistinguishable from the real thing. Within that same 3 year timeframe, it will be able to produce broadcast quality deepfakes as well. A picture will no longer be worth 1000 words; in terms of evidence of truth, it will be worth nothing: in newspapers, on the web, or in court. We're going back to 1800's information ecosystem, where the only way you knew whether something actually happened was the past veracity of the person who told you about it (be it a friend or a reporter.)
There is nothing we can do about AGI. If it's possible, someone will do it, and we'll all have to deal. But there are lots of things that could be done on these two fronts that could improve the world today, right now, and the AGI debate is a distraction from doing them.
Fantastic write up, captures precisely how I have felt about the technology in a much more elegant way than I could have written